Figure 1
Download original image
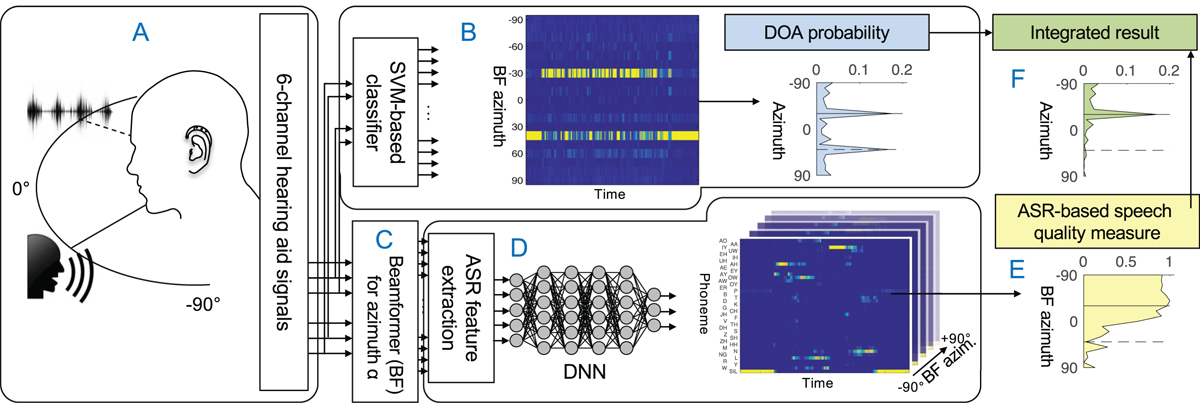
Illustration of the proposed system: (A, Sect. 2.1) A virtual acoustic scene (speaker at −30° and either a spatially diffuse noise or localized noise source at 40°) is captured with a 6-channel behind-the-ear hearing aid. (B, Sect. 2.2) Four channels are used to extract features for sound source localization fed to an SVM-based classifier. This results in a probability for direction of arrival of localized sound sources in the acoustic scene over time, which are averaged over time. (C, Sect. 2.3) A six-channel beamformer is used for spatial signal enhancement. (D, Sect. 2.4) ASR features are extracted from the beamformer signals and used as input to a DNN trained on speech data. This results in phoneme probabilities over time for each beamforming direction. (E, Sect. 2.5) An ASR-based speech quality measure is applied to these probabilities. (F, Sect. 2.6) By integrating information from two processing streams, the speaker at −30° (solid line) is clearly separated from the localized noise (dashed line).
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.